728x90
gensim을 쓰다가 에러가 나서 기록해본다. 흔히 나는 에러는 아닐 것 같다. (아닌가? 예상 외로 사람들이 꽤 찾아본다.)
한글 전처리에서 스페이스 ' ' 로 이어진 두 단어를 한 단어로 처리해서 word2vec 넣고 모델을 저장했다. (ex. 먹고 싶다, 안 되다, 자지 않다 )그런데 저장한 모델을 로드하는데 계속 에러가 남.
#
model.wv.save_word2vec_format('./word2vec/kor_w2v_minioven')
KeyedVectors.load_word2vec_format('./word2vec/kor_w2v_minioven')
#
ValueError: could not convert string to float: '되다'
에러 전체 로그:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_1416545/1536788489.py in <module>
----> 1 KeyedVectors.load_word2vec_format('./word2vec/kor_w2v_minioven', binary=False)
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py in load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype, no_header)
1627
1628 """
-> 1629 return _load_word2vec_format(
1630 cls, fname, fvocab=fvocab, binary=binary, encoding=encoding, unicode_errors=unicode_errors,
1631 limit=limit, datatype=datatype, no_header=no_header,
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py in _load_word2vec_format(cls, fname, fvocab, binary, encoding, unicode_errors, limit, datatype, no_header, binary_chunk_size)
1974 )
1975 else:
-> 1976 _word2vec_read_text(fin, kv, counts, vocab_size, vector_size, datatype, unicode_errors, encoding)
1977 if kv.vectors.shape[0] != len(kv):
1978 logger.info(
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py in _word2vec_read_text(fin, kv, counts, vocab_size, vector_size, datatype, unicode_errors, encoding)
1879 if line == b'':
1880 raise EOFError("unexpected end of input; is count incorrect or file otherwise damaged?")
-> 1881 word, weights = _word2vec_line_to_vector(line, datatype, unicode_errors, encoding)
1882 _add_word_to_kv(kv, counts, word, weights, vocab_size)
1883
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py in _word2vec_line_to_vector(line, datatype, unicode_errors, encoding)
1885 def _word2vec_line_to_vector(line, datatype, unicode_errors, encoding):
1886 parts = utils.to_unicode(line.rstrip(), encoding=encoding, errors=unicode_errors).split(" ")
-> 1887 word, weights = parts[0], [datatype(x) for x in parts[1:]]
1888 return word, weights
1889
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py in <listcomp>(.0)
1885 def _word2vec_line_to_vector(line, datatype, unicode_errors, encoding):
1886 parts = utils.to_unicode(line.rstrip(), encoding=encoding, errors=unicode_errors).split(" ")
-> 1887 word, weights = parts[0], [datatype(x) for x in parts[1:]]
1888 return word, weights
1889
ValueError: could not convert string to float: '되다'
전처리하면서 분명 되다 라는 단어는 걸러냈는데 자꾸 저런 에러가 나니 이상해서 저장된 kor_w2v_minioven 파일을 열고 "되다"를 검색했더니 안 되다 가 검색된다.
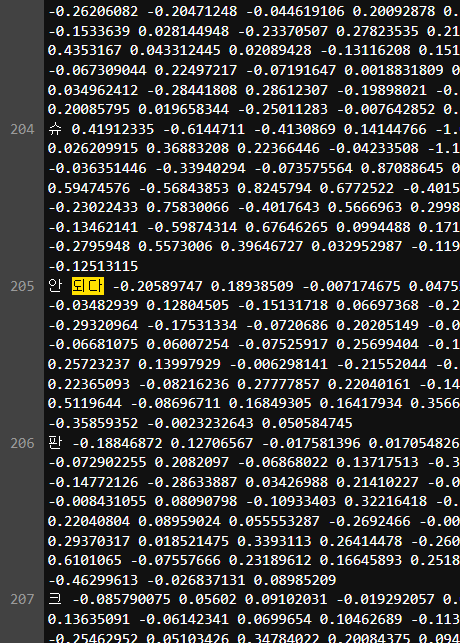
혹시 이게 단어에 스페이스가 들어가서 단어와 벡터를 스플릿하는데 문제가 생기는가 싶어서 스페이스가 들어간 단어들을 스페이스를 없애고 저장→ 로드하니 제대로 로드가 된다.
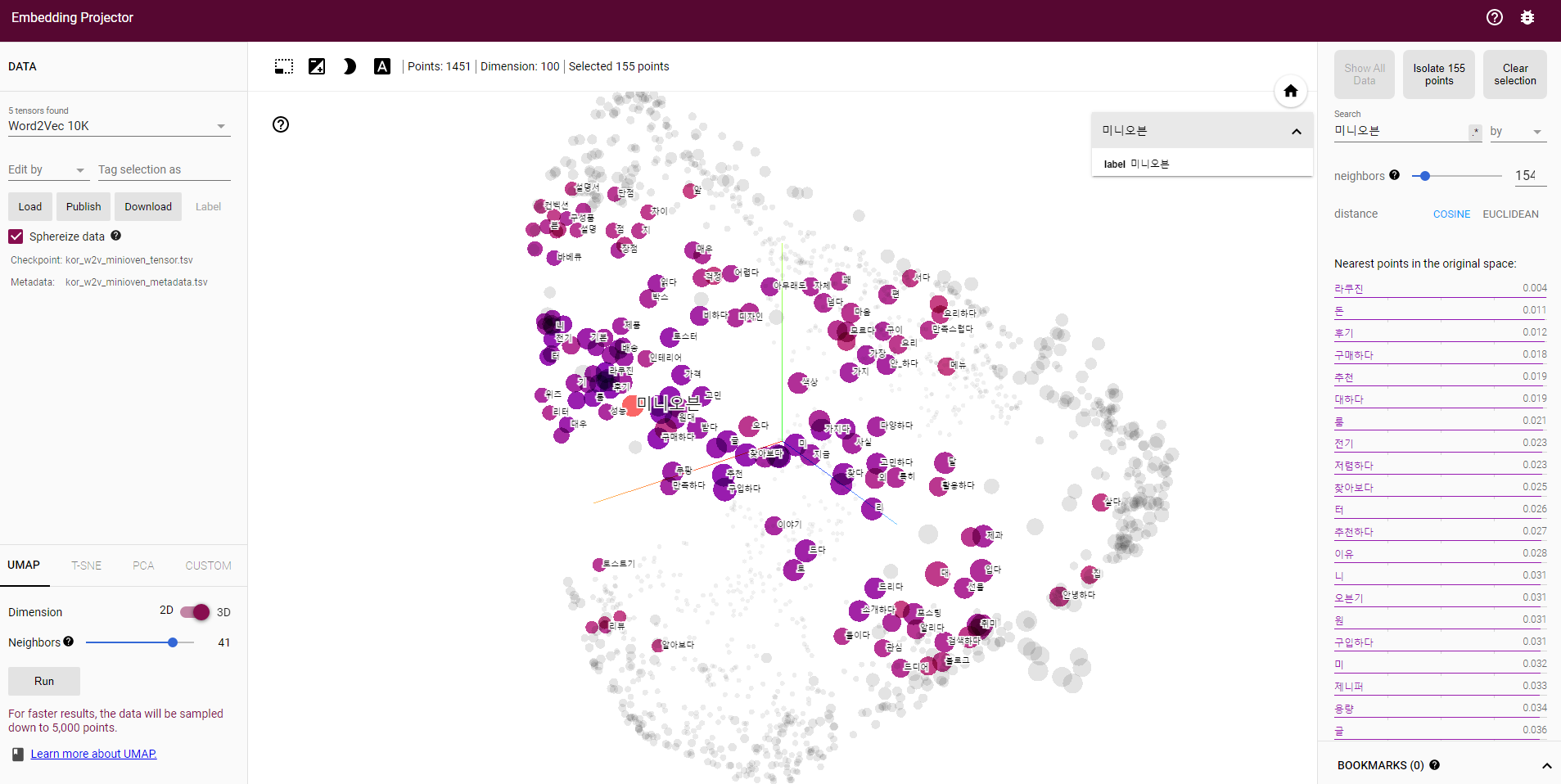
로드가 제대로 되서 시각화를 위한 파일 tsv도 생성 완료.
!python -m gensim.scripts.word2vec2tensor --input ./word2vec/kor_w2v_minioven --output kor_w2v_minioven
미니오븐에 대한 글을 수집해서 전처리한 후 word2vec 로 임베딩해서 의미가 연결되어 있는 단어들을 살펴보았다. 이것에 대한 건 다른 글에.
반응형



