주말에 거사?를 치루고 다시 프로젝트로 돌아왔다. 잘 한 것같아 다행이나 다음 관문이 또 문제...
어쨋거나, 이 프로젝트. 이렇게 저렇게 하면 금방 될줄 알았는데..아니다. 누군가가 정리해준 거나 있는 디비를 가지고 구현하는 게 아니다보니 모든 걸 다 만들어야 한다. DB도 설계해야하고, 데이터도 탐색해야 해서 어떤 데이터를 삭제하고, 수정하고, 보완하고, 어떻게 새로운 데이터를 만들어낼지 찾아야 하고, 결코 빠르게 끝날 일이 아니었다. 이것만 붙잡고 있는 것도 아니니.. DB나 프로젝트 관련 스택에 대해 모르거나 궁금한 것들 찾아보고 정리도 해야 하고.
사실 대충 파이프라인만 만들어낸다 생각하면 아무렇게나 만들 수 있지만 또 그건 무슨 의미가 있고, 그렇게 해서 뭐를 얻어갈까 싶어서 데이터 들여다보면 시간이 순삭..
현재 파이프라인 계획
- 로그를 읽는 파이프라인은 1분 단위로 돌릴 예정이다. 이미 있는 데이터이지만 분단위로 데이터를 가져오게 할 예정이다. 방법은 생각중.
- raw 데이터를 상태를 분석하고 이에 맞게 DB를 설계
- raw 데이터를 상태를 분석하고 전처리 task 추가
- raw 데이터에서 데이터를 분리해 각각에 맞는 DB 테이블에 저장 (ex. user 정보 → user 테이블)
밑은 데이터 탐색한 것들 중 몇 가지이다.
공개 데이터인데 어느정도 정리되어 있겠지하며 좀 믿고있었는데(?) 절대 아니었다. 이 맛에 데이터 보는 것도 있지만..숨은 그림찾기 같은 느낌.
1. 시간 당 로그양
하루 데이터를 빼서 단위 시간 당 로그가 몇 개씩 생성되는지 살펴보았다.
데이터가 크니 더 샘플링을 해서 통계를 내야할 것이다. 만약 데이터가 이것의 몇 배가 된다면 처리하는 서버를 더 띄우고, 카프카 등의 메세지큐를 이용해야겠지? 그럼 서버를 증설하는 지점은 어떤 지표를 가지고 판단해야할까? 로그 데이터를 받아서 처리하고 DB로 보내는 과정은 에어플로우 dag을 통해 작업될텐데 그럼 에어플로우 태스크 처리 타임을 봐야할까.
다 작업하고 후에 옵션으로 카프카(스트림?)도 연습삼아 달아보면 어떨까 생각해봄.
하루 로그양 변화에 주기가 있는지도 살펴볼 예정이다.

단위 시간당(초/분/시) 로그양의 분포. plot이 뭔가 좀 부족하다. 한글패치를 안 해놔서 영어로 적어야 하니 더더욱;

2. dag task에 추가할 전처리 작업들 후보
- varchar 컬럼 중에 문자열길이 truncation 필요 -> spotify에서 받은 데이터로 바꿔넣기
- release name nan값 채워넣기. -> spotify에서 받은 데이터로 바꿔넣기
- z-score로 아웃라이어 제거 후 max값 = varchar size
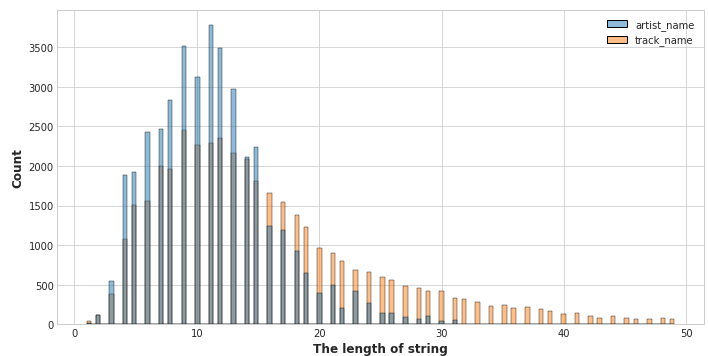
문자열도 그냥 DB에 넣으려고 보니 artist_name을 넣는데 너무 길어서 에러가 난다. 그래서 모든 문자열 컬럼들에 대해 문자열 길이 분포를 조사해보았다.
artist_name은 무려 길이가 400에 가까운 것도 있다.

z-score로 아웃라이어를 제거하니 얼추 max값으로 db컬럼 문자열 길이값을 정하면 될 것 같다.

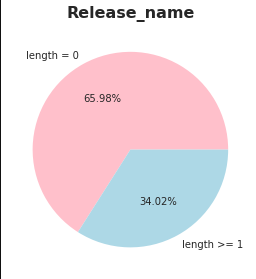
release_name은 null이 허용되는 컬럼이어서 null값이 몇 개나 들어가 있는지 보았다. release_name은 앨범이름으로 추정하고 있어서 다른 정보들을 참조해 spotify에서 가져와 보충할 것이다.
3. 확인 및 제거 데이터
데이터 날짜 다 들어갔는지 확인 (누락부분 채워넣기)
tags 컬럼 삭제. (전체 데이터에서 null값이 95% 이상)
하루 데이터만도 이런데 2년치 데이터엔 무슨 일이 일어나 있을지..허허허
오늘도 평화로운 데이터나라.



