정리:
- 어텐션 메커니즘은 사람이 어떤 사물에 집중하는 것을 모티브로 해서 만들어졌다
- RNN 구조의 문제점을 개선
- 인풋을 인코딩하여 그 정보들을 마지막 hidden state 벡터에 모두 압축하고, 이 벡터와 디코더를 이용해 데이터를 만들어 낼 때 과연 hiden state vector가 모든 정보를 잘 담아내고 있을까? 그렇지 않다.
- 긴 문장을 처리할 때 문제가 생김. 역전파로 저 앞의 단어에 대한 관계를 업데이트하려고 할 때 많은 스텝을 거슬러 올라가면서 반영이 잘 안 될 수도 있다. LSTM이 이론적으로 그 문제를 해결했지만 실제로는 그렇지는 않다.
- 이 문제는 인풋을 어떻게 넣느냐에 따라 결과값이 좋아지거나 나빠지는 것에서 확인할 수 있다. (반대로 넣는다던지, 반복해서 여러번 넣는다던지..)
- 어텐션 구조의 특징
- 각각의 아웃풋을 생성해낼 때마다 모든 인풋을 고려하는 가중치(행렬)를 둔다.
- 기존 RNN에서는 t스텝을 반복하고 나온 마지막 hidden state 만을 고려했다면 어텐션에서는 모든 스텝에서 나온 hidden state를 모두 활용한다
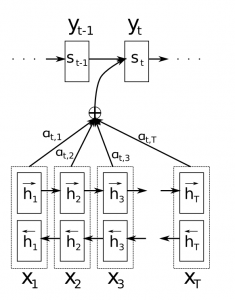
- 훈련 후 이 가중치(행렬)를 살펴보면 각 단어에 대해 어떤 인풋들을 많이 고려했는지 확인할 수 있다.( 모델이 무슨 짓을 해서 그렇게 해석했는지 이해할 수 있음)
- 계산시간이 많이 든다? 각 단어마다 모든 인풋의 관계를 업데이트할테니까?
Background on the Attention Mechanism[텐서플로우 튜토리얼페이지]
We now describe an instance of the attention mechanism proposed in (Luong et al., 2015), which has been used in several state-of-the-art systems including open-source toolkits such as OpenNMT and in the TF seq2seq API in this tutorial. We will also provide connections to other variants of the attention mechanism.
→ (Luong et al., 2015)에 의해 제안된 어텐션 메커니즘 묘사입니다. openNMT 같은 오픈소스 툴킷이나 텐서플로우 seq2seq api에서도 사용되고 있음.
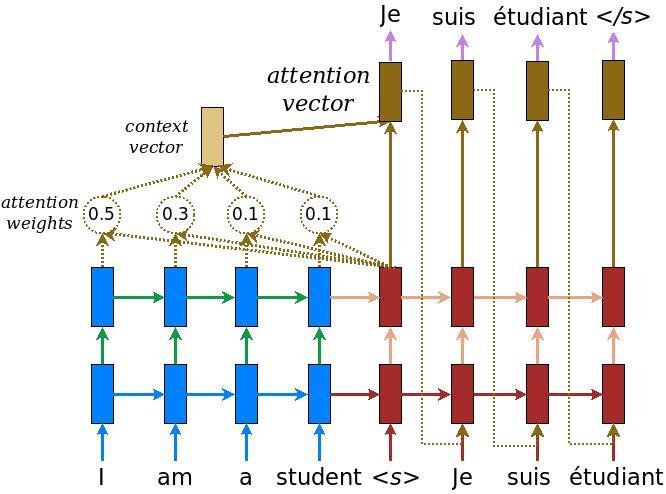
Figure 5. Attention mechanism – example of an attention-based NMT system as described in (Luong et al., 2015) . We highlight in detail the first step of the attention computation. For clarity, we don't show the embedding and projection layers in Figure (2).
As illustrated in Figure 5, the attention computation happens at every decoder time step. It consists of the following stages:
- The current target hidden state is compared with all source states to derive attention weights (can be visualized as in Figure 4(밑에)).
- Based on the attention weights we compute a context vector as the weighted average of the source states.
- Combine the context vector with the current target hidden state to yield the final attention vector
- The attention vector is fed as an input to the next time step (input feeding). The first three steps can be summarized by the equations below:
→ figure5에서 묘사된 것처럼 어텐션 계산은 모든 디코터 타임스텝에서 일어난다.
- 현재 타겟 hidden state 는 모든 소스 state들과 비교되어지고 어텐션 weight(α)를 도출해냄(밑에 figure4)
- 어텐션 weight(α)를 가지고 context 벡터(c)를 계산한다. context 벡터는 소스 state의 weighted average임.(각각의 소스 state가 가중처리된 후 평균)
- context 벡터(c)를 현재 타겟 hidden state와 결합해서 마지막 attention vector(a)를 만들어낸다.
- attention vector(a)는 다음 타임스텝의 인풋으로 사용된다.(input feeding). 1~3의 값들을 식으로 나타내면 다음과 같음:

Here, the function score is used to compared the target hidden state ht with each of the source hidden states h¯s, and the result is normalized to produced attention weights (a distribution over source positions). There are various choices of the scoring function; popular scoring functions include the multiplicative and additive forms given in Eq. (4). Once computed, the attention vector at is used to derive the softmax logit and loss. This is similar to the target hidden state at the top layer of a vanilla seq2seq model. The function f can also take other forms.
→ 여기서 함수 score는 타겟 hidden state h_t와 소스 hidden state h¯_s를 비교하기 위해 사용되고, 결과는 정규화 되서 어텐션 weight로 사용된다.
→ 다양한 score 함수가 있는데 가장 인기있는? 함수는 eq(4) 번처럼 곱과 덧셈 형태가 들어가 있다. 어텐션벡터 a_t가 계산되면 소프트맥스 logit와 loss를 도출하기 위해 사용된다. 어텐션벡터는 seq2seq 모델의 가장 위의 층의 타겟 hidden state 와 유사함.
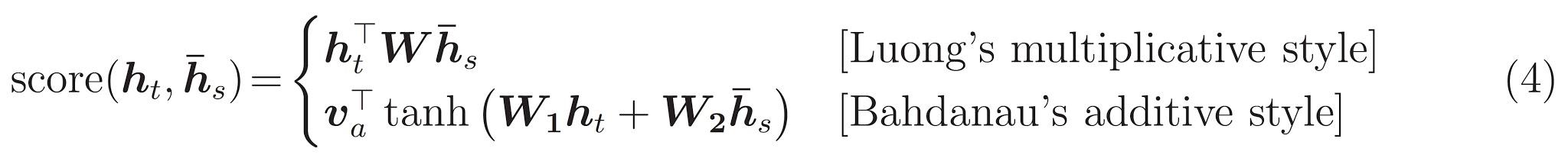
Various implementations of attention mechanisms can be found in attention_wrapper.py.
What matters in the attention mechanism? 어텐션 메커니즘에서 무엇을 고려해야 하는가?
As hinted in the above equations, there are many different attention variants. These variants depend on the form of the scoring function and the attention function, and on whether the previous state ht-1 is used instead of ht in the scoring function as originally suggested in (Bahdanau et al., 2015). Empirically, we found that only certain choices matter. First, the basic form of attention, i.e., direct connections between target and source, needs to be present. Second, it's important to feed the attention vector to the next timestep to inform the network about past attention decisions as demonstrated in (Luong et al., 2015). Lastly, choices of the scoring function can often result in different performance. See more in the benchmark results section.
→ 위에서 보면 알겠지만 어텐션 메커니즘은 score 함수와 어텐션 함수의 다양한 변형에 의존함. (Bahdanau et al., 2015)에서는 score 함수에서 ht 대신 ht-1을 활용했음.
→ 경험적으로 어텐션에서는 다음과 같은 것들이 중요
- 어텐션의 기본형태(타겟과 소스 사이의 직접적인 연결)가 필요하고,
- (네트워크에게 과거 어텐션 deicision 정보를 제공해야 하니까) 어텐션벡터가 다음 타임스텝에서 이용되야 함.
- 마지막으로 scoring function 선택이 다른 퍼포먼스를 가져온다.

Figure 4. Attention visualization – example of the alignments between source and target sentences. Image is taken from (Bahdanau et al., 2015).
Attention and Memory in Deep Learning and NLP[원문링크]
A recent trend in Deep Learning are Attention Mechanisms. In an interview, Ilya Sutskever, now the research director of OpenAI, mentioned that Attention Mechanisms are one of the most exciting advancements, and that they are here to stay. That sounds exciting. But what are Attention Mechanisms?
Attention Mechanisms in Neural Networks are (very) loosely based on the visual attention mechanism found in humans. Human visual attention is well-studied and while there exist different models, all of them essentially come down to being able to focus on a certain region of an image with “high resolution” while perceiving the surrounding image in “low resolution”, and then adjusting the focal point over time.
→ NN에서 어텐션 메커니즘은 사람의 비주얼 어텐션 매커니즘을 (아주 약하지만) 기반으로 하고 있다. 사람의 비주얼 어텐션은 잘 연구되어 있고 그에 따른 여러 모델들이 존재한다. 그것들 모두가 필수적으로 이미지의 고해상도? 부분에 집중하고 동시에 저해상도의 주변이미지를 감지한다. 이를 바탕으로 시간에 따라 초점을 수정할 수 있게 만들어져 있다.
perceive - 감지하다
resolution - 여기선 해상도로 해석?
focal - 중심, 초점의
comprehensive - 종합적인, 포괄적인
Attention in Neural Networks has a long history, particularly in image recognition. Examples include Learning to combine foveal glimpses with a third-order Boltzmann machine or Learning where to Attend with Deep Architectures for Image Tracking. But only recently have attention mechanisms made their way into recurrent neural networks architectures that are typically used in NLP (and increasingly also in vision). That’s what we’ll focus on in this post.
- 어텐션 매커니즘은 최근들어(2016년도 글임) RNN구조에서 그 길을 만들어가고 있다. (RNN은 보통 NLP(Natural Language Processing 자연어처리)에서 자주 쓰이고 ,비전에서도 사용이 증가하고 있음)
What problem does Attention solve? 어텐션은 무엇을 해결하는가?
To understand what attention can do for us, let’s use Neural Machine Translation (NMT) as an example. Traditional Machine Translation systems typically rely on sophisticated feature engineering based on the statistical properties of text. In short, these systems are complex, and a lot of engineering effort goes into building them.
Neural Machine Translation systems work a bit differently.
In NMT, we map the meaning of a sentence into a fixed-length vector representation and then generate a translation based on that vector.
→ NMT에서는 문장의 의미를 고정된 길이의 벡터로 매핑하고, 그다음 그 벡터를 기반으로 해석을 만들어낸다.
By not relying on things like n-gram counts and instead trying to capture the higher-level meaning of a text, NMT systems generalize to new sentences better than many other approaches.
→ n-gram counts 같은 방식에 의존하지 않고 대신 텍스트의 더 높은 레벨의 의미를 캐치하려고 노력함으로서 NMT 시스템이 다른 시도들보다 더 나은 새로운 문장등을 생성한다.
Perhaps more importantly, NTM systems are much easier to build and train, and they don’t require any manual feature engineering. In fact, a simple implementation in Tensorflow is no more than a few hundred lines of code.
→ 다른 방식보다 만들고 훈련하는 것이 쉬워서 어떤 메뉴얼 피처 엔지니어링이 필요하지 않다. 텐서플로우에 백 몇 줄로 구현가능
Most NMT systems work by encoding the source sentence (e.g. a German sentence) into a vector using a Recurrent Neural Network,
→ (Most NMT systems - 소스 문장을 RNN을 이용해 벡터로 '엔코딩'함으로서 작동한다. 엔코딩의 의미)
and then decoding an English sentence based on that vector, also using a RNN.
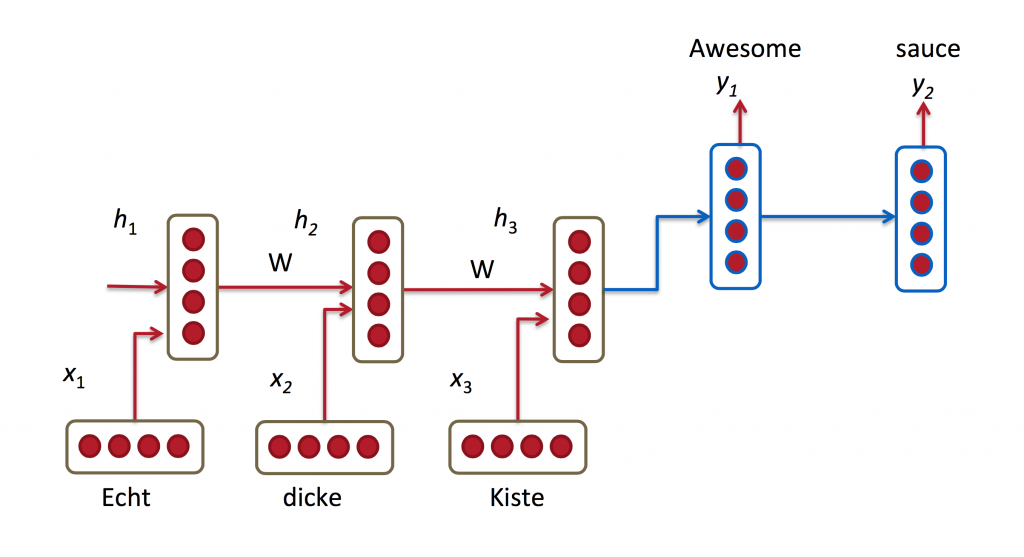
In the picture above, “Echt”, “Dicke” and “Kiste” words are fed into an encoder,
and after a special signal (not shown) the decoder starts producing a translated sentence.
The decoder keeps generating words until a special end of sentence token is produced. Here, the 
If you look closely, you can see that the decoder is supposed to generate a translation solely based on the last hidden state (

solely - 단독으로, 오로지
relevant - 적절한
semantically - 의미상, 의미론적으로
highly - 대단히, 매우
correlate - 연관성이 있다.
Still, it seems somewhat unreasonable to assume that we can encode all information about a potentially very long sentence into a single vector and then have the decoder produce a good translation based on only that.
→ 여전히 비합리적인듯해 보임. 뭐가? 우리가 잠재적으로 매~우 긴 문장을 하나의 벡터에 인코딩할 수 있다 가정하고, 오직 그 벡터만을 가지고 디코더가 좋은 해석을 만들어낸다는걸 말이지..
Let’s say your source sentence is 50 words long. The first word of the English translation is probably highly correlated with the first word of the source sentence. But that means decoder has to consider information from 50 steps ago, and that information needs to be somehow encoded in the vector.
→ 50단어의 긴 문장을 소스로 가지고 있다고 생각하자. 영어번역의 첫 단어는 소스 문장의 첫 단어와 매우 연관성이 높다. 이 말은 디코더가 50스텝 전의 정보를 고려해야한다는 뜻이고 그 정보는 벡터 안에 어떤 방식으로 인코딩되어있어야 함.
Recurrent Neural Networks are known to have problems dealing with such long-range dependencies. In theory, architectures like LSTMs should be able to deal with this, but in practice long-range dependencies are still problematic. For example, researchers have found that reversing the source sequence (feeding it backwards into the encoder) produces significantly better results because it shortens the path from the decoder to the relevant parts of the encoder. Similarly, feeding an input sequence twice also seems to help a network to better memorize things.
→ RNN은 이런 long-range dependencies를 다루는데 문제을 가지고 있는 걸로 알려져 있다. 이론적으로 LSTM같은 구조가 이 문제를 어느정도 해결할 수 있다고 말하지만 실제 상황에선 여전히 문제임. 예를 들어 리서처가 소스시퀀스를 반대로 넣어서 돌렸더니 훠얼씬 좋은 결과를 얻었는데 왜냐하면 디코더에서 엔코더의 적절한 파트까지 가는 경로가 짧아졌기 때문임. (문장 길이, 방향에 따라 결과의 일관성이 보장되지 않는다)
예:
I consider the approach of reversing a sentence a “hack”. It makes things work better in practice, but it’s not a principled solution. Most translation benchmarks are done on languages like French and German, which are quite similar to English (even Chinese word order is quite similar to English). But there are languages (like Japanese) where the last word of a sentence could be highly predictive of the first word in an English translation. In that case, reversing the input would make things worse. So, what’s an alternative? Attention Mechanisms.
(문장을 거꾸로 넣었을 때 성능이 좋을 때가 있고, 아닐 때도 있다 (일본어 같은 경우 처음을 보면 마지막에 어떤 단어가 나올지 예측할 수 있는데 이때 거꾸로 문장을 넣으면 더 나쁘게 작동))
With an attention mechanism we no longer try encode the full source sentence into a fixed-length vector.
→ 어텐션 메커니즘을 이용하면 우리는 전체의 소스시퀀스를 고정된 길이의 벡터로 인코딩할 필요가 없어진다.
Rather, we allow the decoder to “attend” to different parts of the source sentence at each step of the output generation.
→ 그 대신 우리는 디코더가 각각의 아웃풋 생성 스텝에서 소스문장의 다른 파트들에 주의를 기울이게 만들 수 있다.
Importantly, we let the model learn what to attend to based on the input sentence and what it has produced so far. So, in languages that are pretty well aligned (like English and German) the decoder would probably choose to attend to things sequentially. Attending to the first word when producing the first English word, and so on. That’s what was done in Neural Machine Translation by Jointly Learning to Align and Translate and look as follows:
→ 중요한 것은, 우리가 모델로 하여금 ,인풋 문장과 지금까지 생성한 것들을 기반으로 한 것들에 주의를 기울이게 만들 수 있음. (여기가 해석이 모호한데..)
Here, The 





→ x는 소스문장의 단어, y는 디코더로부터 생성된 아웃풋. 각각의 디코더 아웃풋 단어 y_t는 모든 인풋상태의 가중치 결합에 의존하고 있음. a는 weight인데, 각각의 인풋상태가 아웃풋에서 고려되야 하는지를 정의한다.
만약
A big advantage of attention is that it gives us the ability to interpret and visualize what the model is doing. For example, by visualizing the attention weight matrix
→ 어텐션의 큰 장점은 이것이 우리에게 모델이 무엇을 하는지 해석하고 시각화한다는 것임.
→ 예를 들어 어텐션 가중치 매트릭스 a를 시각화함으로서 문장이 번역되었을 때 모델이 어떻게 해석했는지 이해할 수 있음

Here we see that while translating from French to English, the network attends sequentially to each input state, but sometimes it attends to two words at time while producing an output, as in translation “la Syrie” to “Syria” for example.
→ 위의 그림에서 불어를 영어로 해석할 때 네트워크가 순차적으로(그림처럼 단어 순서에 맞춰 인풋과 아웃풋이 연관되어 있는 직선구조) 각각의 인풋상태에 주의를 기울이는 것을 확인할 수 있다.
그렇지만 때때로 네트워크는 아웃풋을 생성할 때 동시에 2단어에 주의를 기울이기도 한다(la Syria → Syria)
( 만일 보통 RNN이었다면 첫번째 output 'Destination'과 연관된 단어가 가장 마지막 인풋인 Chimiques를 더 반영하고 있을지도 모른다. )
The Cost of Attention
If we look a bit more look closely at the equation for attention we can see that attention comes at a cost.
We need to calculate an attention value for each combination of input and output word.
If you have a 50-word input sequence and generate a 50-word output sequence that would be 2500 attention values.
→한 아웃풋마다 인풋의 50개의 단어에 대해 attention 수치를 수집하니 아웃풋 개수 50개 * 인풋 개수 50 = 2500
That’s not too bad, but if you do character-level computations and deal with sequences consisting of hundreds of tokens the above attention mechanisms can become prohibitively expensive.
→ 그치만 만약 단어가 아닌 캐릭터레벨 계산을 하면 난리나겠지..cost가 장난아닐거임
counterintuitive -직관에 어긋나는, 반 직관적인
be supposed to - ~라고들 함 / ~해야되, ~하기로 되어있음
akin - ~와 유사한
misnomer - 부적적한 명칭
Actually, that’s quite counterintuitive.
→실제로 이건 비직관적임 (갑자기 웬 비직관적? 사람의 어텐션 구조랑 비교했을 때 비직관적이란 것임..밑에 읽어보면 나옴)
Human attention is something that’s supposed to save computational resources. By focusing on one thing, we can neglect many other things. But that’s not really what we’re doing in the above model.
→ 사람은 실제로 어떤 것에 집중하면 나머지를 무시하잖아. 그런데 저 모델에서는 모든 요소에 대해 고려하고 있지.
We’re essentially looking at everything in detail before deciding what to focus on. Intuitively that’s equivalent outputting a translated word, and then going back through all of your internal memory of the text in order to decide which word to produce next.
→ 우리는 필수적으로 어떤 것에 집중하기 전에 모든 것들을 세세하게 보지. 직관적으로 이건 우리의 내부의 모든 기억으로 돌앙와서 어떤 단어를 다음에 만들어낼지 결정하고 해석된 단어를 내놓는 것과 같은 맥락임
That seems like a waste, and not at all what humans are doing.
→ 이건 낭비처럼 보이지만 모든 사람들이 하는 것과 전혀 다르지 않다
In fact, it’s more akin to memory access, not attention, which in my opinion is somewhat of a misnomer (more on that below). Still, that hasn’t stopped attention mechanisms from becoming quite popular and performing well on many tasks.
→ 사실 이건 메모리 억세스와 유사하고, 내 의견으로는 어텐션이라는 해석은 부적절한 것 같다. 하지만 이걸로 요즘 잘 나가기 시작한 어텐션 메커니즘을 막을 수는 없지.
An alternative approach to attention is to use Reinforcement Learning to predict an approximate location to focus to. That sounds a lot more like human attention, and that’s what’s done in Recurrent Models of Visual Attention.
→ 집중할 근사적인 위치를 유추하기 위해서 어텐션의 대안으로는 강화학습을 이용하는 것. 이게 좀 더 사람의 어텐션과 비슷한 것 같다.
Attention beyond Machine Translation
So far we’ve looked at attention applied to Machine Translation.
But the same attention mechanism from above can be applied to any recurrent model. So let’s look at a few more examples.
→ 계속 머신 번역에 적용된 어텐션을 봤는데 위와 같은 어텐션 매커니즘은 recurrent 모델 어디에나 적용될 수 있다.
In Show, Attend and Tell the authors apply attention mechanisms to the problem of generating image descriptions.
→ Show, Attend and Tell 저자들은 어텐션 매커니즘을 이미지 묘사 문제에 사용했음
They use a Convolutional Neural Network to “encode” the image, and a Recurrent Neural Network with attention mechanisms to generate a description. By visualizing the attention weights (just like in the translation example), we interpret what the model is looking at while generating a word:
→ 그들은 이미지를 "인코딩하기 위해" CNN을 사용하고 RNN 와 어텐션 매커니즘은 묘사를 한다. 어텐션 가중치를 시각화함으로서 우리는 모델이 단어를 생성할 때 무엇을 봤는지 해석할 수 있다

(이건 이해가 잘 안 되었음..)
In Grammar as a Foreign Language, the authors use a Recurrent Neural Network with attention mechanisk to generate sentence parse trees.
The visualized attention matrix gives insight into how the network generates those trees:

In Teaching Machines to Read and Comprehend, the authors use a RNN to read a text, read a (synthetically generated) question, and then produce an answer.
By visualizing the attention matrix we can see where the networks “looks” while it tries to find the answer to the question:

Attention = (Fuzzy) Memory?
refer back to - 에 다시 회부하다.~을 다시 언급하다
The basic problem that the attention mechanism solves is that it allows the network to refer back to the input sequence, instead of forcing it to encode all information into one fixed-length vector.
→ 어텐션 메커니즘이 해결한 기본적인 문제는, 네트워크가 모든 정보를 인코딩해서 고정된 길이의 벡터에 집어넣지 않고 대신 인풋 시퀀스에 다시 그것을 언급하게 만든 것이다.
As I mentioned above, I think that attention is somewhat of a misnomer.
→ 위에서 언급했지만 내 생각엔 어텐션(이란 표현)은 잘못 표현된 것 같아.
Interpreted another way, the attention mechanism is simply giving the network access to its internal memory, which is the hidden state of the encoder.
→ 어텐션 매커니즘은 단순히 인코더의 히든 스테이트인 내부 메모리에 네트워크가 접근하게 해준거야.
In this interpretation, instead of choosing what to “attend” to, the network chooses what to retrieve from memory.
→ 이 해석을 바탕으로 하면 눈여겨 볼 무언가를 선택한다기보다 네트워크가 메모리로부터 검색한 무언가를 선택한 거지.
Unlike typical memory, the memory access mechanism here is soft, which means that the network retrieves a weighted combination of all memory locations, not a value from a single discrete location. Making the memory access soft has the benefit that we can easily train the network end-to-end using backpropagation (though there have been non-fuzzy approaches where the gradients are calculated using sampling methods instead of backpropagation).
→ 다른 보통의 메모리와는 다르게 여기에서 메모리접근 메커니즘은 soft한데, 이 soft의 뜻은 네트워크가 하나의 이산적인 위치로부터의 값들이 아닌 모든 메모리 위치에서의 가중치의 결합을 가져온 것을 말한다. 메모리 접근은 soft 하게 만들면서 얻을 수 있는 이익은 우리가 쉽게 백프로파게이션을 이용해 네트워크를 end-to-end로 훈련시킬 수 있는 것이다. (백프로파게이션 대신 샘플링메소드로 계산된 기울기를 이용하는 non-fuzzy(?)한 접근법들도 있긴하다)
Memory Mechanisms themselves have a much longer history. The hidden state of a standard Recurrent Neural Network is itself a type of internal memory. RNNs suffer from the vanishing gradient problem that prevents them from learning long-range dependencies. LSTMsimproved upon this by using a gating mechanism that allows for explicit memory deletes and updates.
→ 메모리 메커니즘 자체는 긴 역사를 가지고 있다. 표준 RNN 의 히든 스테이트는 그 자체로 내부 메모리이다. RNN 모델들은 vanishing gradient problem 로 고생하는데 이 문제는 long-range dependencies learning을 못하게 방해한다. LSTM이 gating 메커니즘을 사용하여 이 부분을 향상시키긴 했다. 이 gating 메커니즘은 명시적인 메모리 삭제와 업데이트를 할 수 있게 해준다.
다른 메모리 네트워크의 예시? End-to-End Memory Networks, Neural Turing Machines
The trend towards more complex memory structures is now continuing. End-to-End Memory Networks allow the network to read same input sequence multiple times before making an output, updating the memory contents at each step.
→ 더 복잡한 메모리 구조를 향한 트렌드는 여전히 진행중이다. End-to-End Memory Networks는 네트워크가 똑같은 인풋시퀀스를 여러번 읽고 메 스텝마다 메모리 컨텐츠를 업데이트 하고 아웃풋을 만들어낸다.
For example, answering a question by making multiple reasoning steps over an input story. However, when the networks parameter weights are tied in a certain way, the memory mechanism inEnd-to-End Memory Networks identical to the attention mechanism presented here, only that it makes multiple hops over the memory (because it tries to integrate information from multiple sentences).
Neural Turing Machines use a similar form of memory mechanism, but with a more sophisticated type of addressing that using both content-based (like here) and location-based addressing, allowing the network to learn addressing pattern to execute simple computer programs, like sorting algorithms.
It’s likely that in the future we will see a clearer distinction between memory and attention mechanisms, perhaps along the lines of Reinforcement Learning Neural Turing Machines, which try to learn access patterns to deal with external interfaces.
→ 미래에는 어텐션 메커니즘과 메모리 사이의 차이를 볼 수 있을 것.



